1편 [Prometheus] 왜 다들 프로메테우스를 사용할까
2편 [Prometheus] Label 하나가 시스템을 느리게 만든다 - 1. Metric, Label, TimeSeries
3편 [Prometheus] Label 하나가 시스템을 느리게 만든다 - 2. Cardinality
앞선 글에서는 Prometheus의 Metric, Label, TimeSeries, Cardinality를 살펴봤다.
이제 한 가지 질문이 남는다.
Prometheus Cardinality가 Datadog에서는 왜 비용이 되는 걸까?
Datadog Custom Metrics 비용이 예상보다 크게 나오는 경우가 있다.
이때 원인을 Datadog에서만 찾으면 조금 늦다.
대부분의 시작점은 Prometheus Metric 설계에 있다.
Datadog Custom Metrics는 무엇을 기준으로 계산할까
Datadog 공식 문서를 보면 Custom Metric은 단순히 “Metric 이름”만으로 계산되지 않는다.
Datadog은 Custom Metric을 다음 조합으로 식별한다.
Metric name + tag values + host tag공식 문서에서도 Custom Metric은 Metric 이름과 Tag 값 조합으로 고유하게 식별된다고 설명한다.
- Datadog Custom Metrics Billing
https://docs.datadoghq.com/account_management/billing/custom_metrics/
- Datadog Custom Metrics
https://docs.datadoghq.com/metrics/custom_metrics/
즉, 중요한 것은 Metric 이름 하나가 아니다.
Unique TimeSeries다.
이전 글에서 본 Prometheus 구조와 거의 같은 이야기다.

Datadog에서는 이 TimeSeries 조합이 Custom Metrics 비용으로 이어질 수 있다.
Prometheus에서는 하나의 Metric처럼 보인다
예를 들어 이런 Metric이 있다고 해보자.
http_requests_total처음에는 단순해 보인다.
하지만 실제 Prometheus Metric은 보통 이렇게 생겼다.
http_requests_total{
method="GET",
status="200",
service="api"
}여기까지는 괜찮다.
method, status, service 정도는 값의 범위가 어느 정도 제한적이다.
그런데 여기에 이런 Label이 붙기 시작하면 이야기가 달라진다.
user_id="123456"
request_id="a8f3..."
pod="api-7d8f9f7b8-x2klm"
path="/users/123456/orders/98765"이 순간부터 Metric은 더 이상 하나가 아니다.
Label 조합만큼 TimeSeries가 늘어난다.
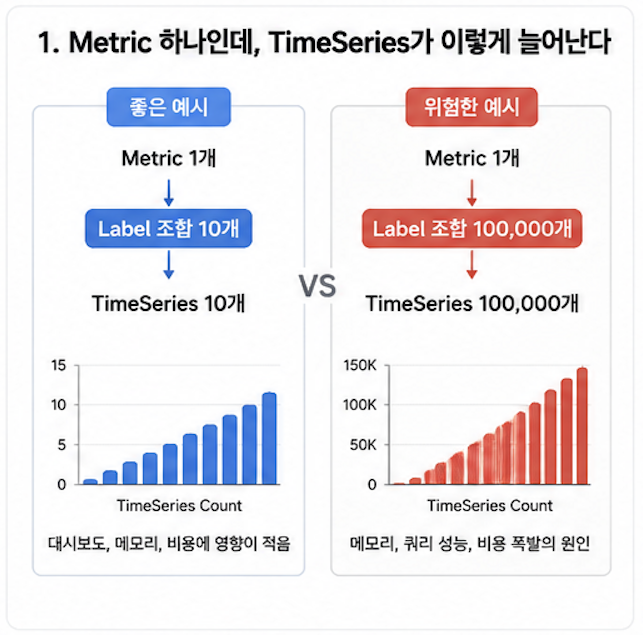
Prometheus에서는 Cardinality 문제고,
Datadog에서는 Custom Metrics 비용 문제가 된다.
Datadog이 비용을 만드는 게 아니다
여기서 오해하면 안 된다.
Datadog이 갑자기 비용을 만들어내는 것이 아니다.
Prometheus에서 이미 만들어진 TimeSeries 구조를 Datadog이 수집하고,
그 조합이 Custom Metrics 과금 기준에 포함
되는 것이다.
구조를 단순하게 보면 이렇다.

Datadog OpenMetrics Integration을 사용하면 Prometheus 형식의 Metric을 Datadog Agent가 수집할 수 있다.
- Datadog OpenMetrics Integration
https://docs.datadoghq.com/integrations/openmetrics/
이때 수집된 Metric이 Datadog의 기본 Integration Metric이 아니라면 Custom Metrics로 계산될 수 있다.
즉,
Prometheus Cardinality가 Datadog Custom Metrics 비용으로 이어질 수 있다.
이게 핵심이다.
숫자로 보면 더 잘 보인다
예를 들어 이런 Metric이 있다고 가정해보자.
http_request_duration_seconds_bucketLabel은 다음과 같다.
method = 4개
status = 5개
service = 20개
path = 100개
bucket(le) = 10개대략 계산하면:
4 × 5 × 20 × 100 × 10 = 400,000 TimeSeriesMetric 이름은 하나인데 TimeSeries는 40만 개가 될 수 있다.
여기에 pod Label까지 붙으면?
pod = 300개
400,000 × 300 = 120,000,000 TimeSeries이쯤 되면 단순히 “Metric 하나 추가했다”가 아니다.
작은 Label 하나가 관측 시스템 전체에 영향을 준다.
Prometheus에서는 메모리와 쿼리 성능 문제가 되고,
Datadog에서는 Custom Metrics 비용 문제가 된다.
특히 위험한 Label
운영에서 특히 조심해야 하는 Label은 대체로 비슷하다.
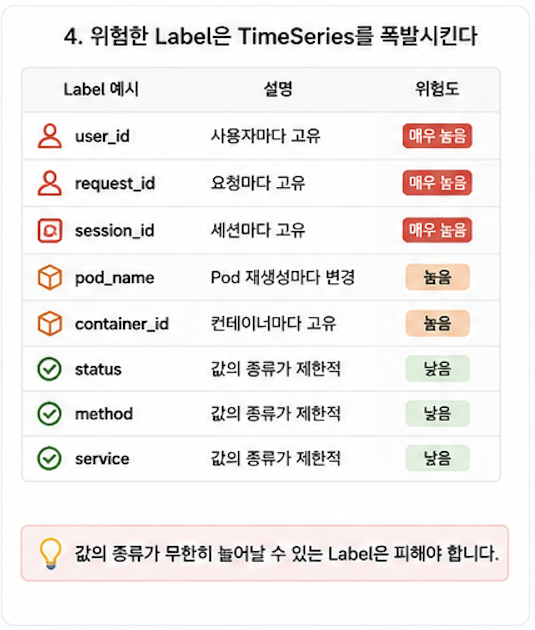
| Label | 위험한 이유 |
|---|---|
| `user_id` | 사용자 수만큼 증가 |
| `request_id` | 요청마다 값이 달라짐 |
| `session_id` | 세션 수만큼 증가 |
| `container_id` | 컨테이너 재생성마다 변경 |
| `pod` | 배포와 스케일링에 따라 계속 변경 |
| `path` | `/users/1234`처럼 동적 값이 섞이면 폭발 |
| `le` | Histogram Bucket마다 TimeSeries 생성 |
특히 Kubernetes 환경에서는 pod, container_id, namespace, deployment, job 같은 Label이 자주 붙는다.
모두 나쁜 Label은 아니다.
다만 비용 관점에서는 반드시 구분해야 한다.
운영에 필요한 Label인가?
아니면 그냥 붙어있는 Label인가?이 질문을 해야 한다.
Histogram은 한 번 더 조심해야 한다
Histogram Metric은 특히 조심해야 한다.

예를 들어 Prometheus Histogram은 보통 이런 Metric을 만든다.
http_request_duration_seconds_bucket
http_request_duration_seconds_sum
http_request_duration_seconds_count여기서 _bucket은 le Label을 가진다.
le="0.1"
le="0.3"
le="0.5"
le="1"
le="3"
le="5"
le="+Inf"Bucket이 10개면 같은 Label 조합도 10배가 된다.
그래서 Histogram은 유용하지만,
무심코 많이 만들면 Custom Metrics 비용에도 영향을 준다.
응답시간을 보고 싶어서 만든 Metric이
나중에는 비용의 주범이 될 수 있다.
참 억울하지만, 관측의 세계는 원래 약간 그런 맛이 있다.
Datadog에서 어디를 봐야 할까
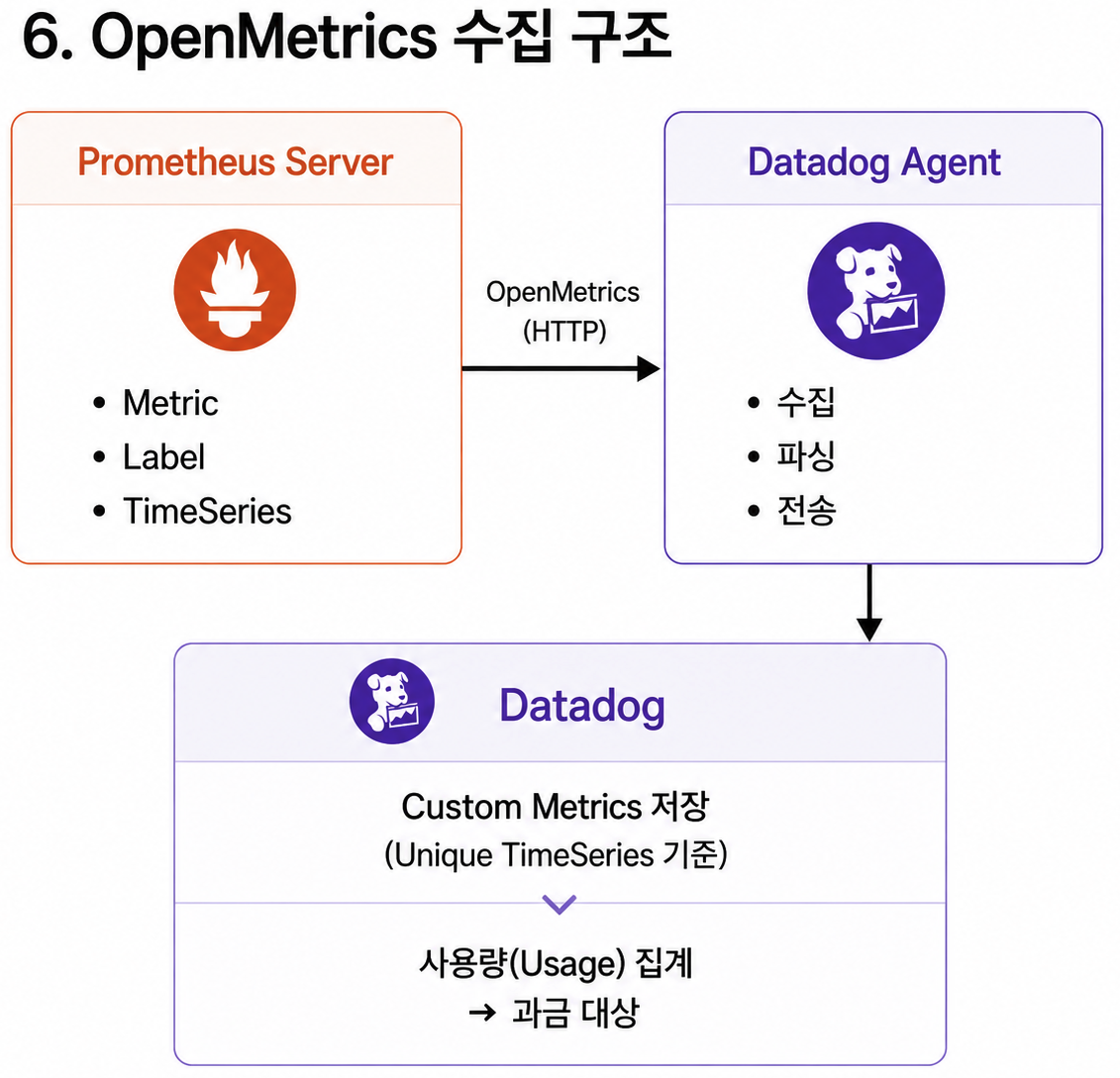
Custom Metrics 비용을 줄이려면 먼저 어디서 많이 발생하는지 봐야 한다.
Datadog에서는 다음 화면을 확인해야 한다.
1. Metrics Summary
Metric별로 어떤 Tag가 붙어 있는지 확인할 수 있다.
- Metrics Summary
https://docs.datadoghq.com/metrics/summary/
여기서 봐야 하는 것은 단순 Metric 이름이 아니다.
이 Metric에 어떤 Tag가 붙어 있는가?
Tag 값이 얼마나 다양하게 생성되는가?이걸 봐야 한다.
2. Usage / Billing
Custom Metrics 사용량이 실제로 어떻게 집계되는지 확인한다.
- Datadog Pricing / Billing
https://docs.datadoghq.com/account_management/billing/pricing/
공식 문서에서도 Custom Metric은 Metric 이름, host ID, tag 조합의 고유한 조합으로 계산되며, 월간 평균 기준으로 과금된다고 설명한다.
즉, 특정 시간에 잠깐 튄 값보다
계속 유지되는 고카디널리티 Metric이 더 위험할 수 있다.
FinOps 관점 체크리스트
Datadog Custom Metrics를 줄이려면 Datadog 화면만 보면 안 된다.
Prometheus Metric 설계부터 봐야 한다.

줄이는 방향은 앞단일수록 좋다
Custom Metrics를 줄이는 방법은 여러 가지가 있다.
Application
↓
Exporter
↓
Prometheus
↓
Datadog Agent
↓
Datadog가장 좋은 위치는 앞단이다.
1. 애플리케이션에서 불필요한 Label을 만들지 않는다.
2. Exporter 설정에서 불필요한 Metric을 줄인다.
3. Prometheus metric_relabel_configs로 저장 전 제거한다.
4. Datadog OpenMetrics 설정에서 필요한 Metric만 보낸다.
5. Datadog에서 Usage를 확인하고 다시 조정한다.
뒤에서 막을수록 이미 늦다.
가장 좋은 Metric은 삭제한 Metric이 아니라,
애초에 생성되지 않은 Metric이다.
무조건 줄이는 게 정답은 아니다
여기서 중요한 점이 있다.
FinOps는 데이터를 무조건 줄이는 일이 아니다.
관측 데이터는 장애 대응과 서비스 운영에 필요하다.
문제는 가치 없는 데이터다.
장애 대응에 쓰이지 않고
Alert에도 쓰이지 않고
Dashboard에서도 보지 않고
비용만 만드는 Metric이런 것들을 줄이는 것이 FinOps다.
그러니까 목표는 단순 절감이 아니다.
필요한 데이터는 남기고, 가치 없는 조합을 제거하는 것.
이게 Observability FinOps의 핵심이다.
마무리
이번 시리즈에서는 Prometheus가 왜 Kubernetes 시대의 표준처럼 사용되는지부터 시작해서,
Metric, Label, TimeSeries, Cardinality까지 살펴봤다.
그리고 마지막으로 Datadog Custom Metrics 비용까지 연결했다.
정리하면 이렇다.
Label 증가
↓
TimeSeries 증가
↓
Cardinality 증가
↓
Datadog Custom Metrics 증가
↓
비용 증가Datadog 비용은 Datadog에서만 시작되지 않는다.
Prometheus Metric 설계에서 시작된다.
결국 Observability 비용은 도구의 문제가 아니라
데이터 설계의 문제다.
'IT > Cloud' 카테고리의 다른 글
| [Prometheus] Label 하나가 시스템을 느리게 만든다 - 2. Cardinality (0) | 2026.06.21 |
|---|---|
| [Prometheus] Label 하나가 시스템을 느리게 만든다 - 1. Metric, Label, TimeSeries (0) | 2026.06.21 |
| [Prometheus] 왜 다들 프로메테우스를 사용할까 (0) | 2026.05.31 |
| [DevOps] 왜 DevOps는 결국 GitOps로 향하게 되었을까 (0) | 2026.05.17 |
| Alpine Linux 에서 파이썬을 사용하면 안되는 이유 (0) | 2026.02.24 |




댓글